
前言
(感觉写的很乱很乱,请勿参考)
现在重新命名我的处理器核叫做zen-core,禅芯,以后写核就叫做修禅心,也算是谐音吧hhhh,主要是总是叫做npc实在是太没有特点了
我首先根据我之前探索出的框架重新创了一个repo,然后打算全部重构一遍,用之前的框架,我可以单独例化一个模块,比如说ALU,然后完全根据这个模块做优化,包括时序面积分析等等,也就是说,elaborate的粒度从design级别到module级别了,然后可以根据这个模块单独写独立于其他的专用配置文件,然后根据专用配置文件(.json)elaborate一个模块,详情见我之前的那篇文章,以及chisel-nix的写法
然后开这篇文章是为了记录我重构模块以及顺便优化面积的一系列经历
ALU
首先根据之前的alu写了现在的alu(完全没变)
面积是1858.542000,时序是880多mhz
究竟采用什么样的优化思路呢,我想了很久,however,我觉得无论如何,第一步首先是了解你的设计,意思是你的头脑中要有一个你的设计大致的电路框图,其实也不一定需要门级的描述,可以稍微更高一点的抽象,也就是微操作不一定需要门级,可以更高级,产生这个想法是我正好想到了firrtl,我觉得这个中间表示是一个很好的分析切入点
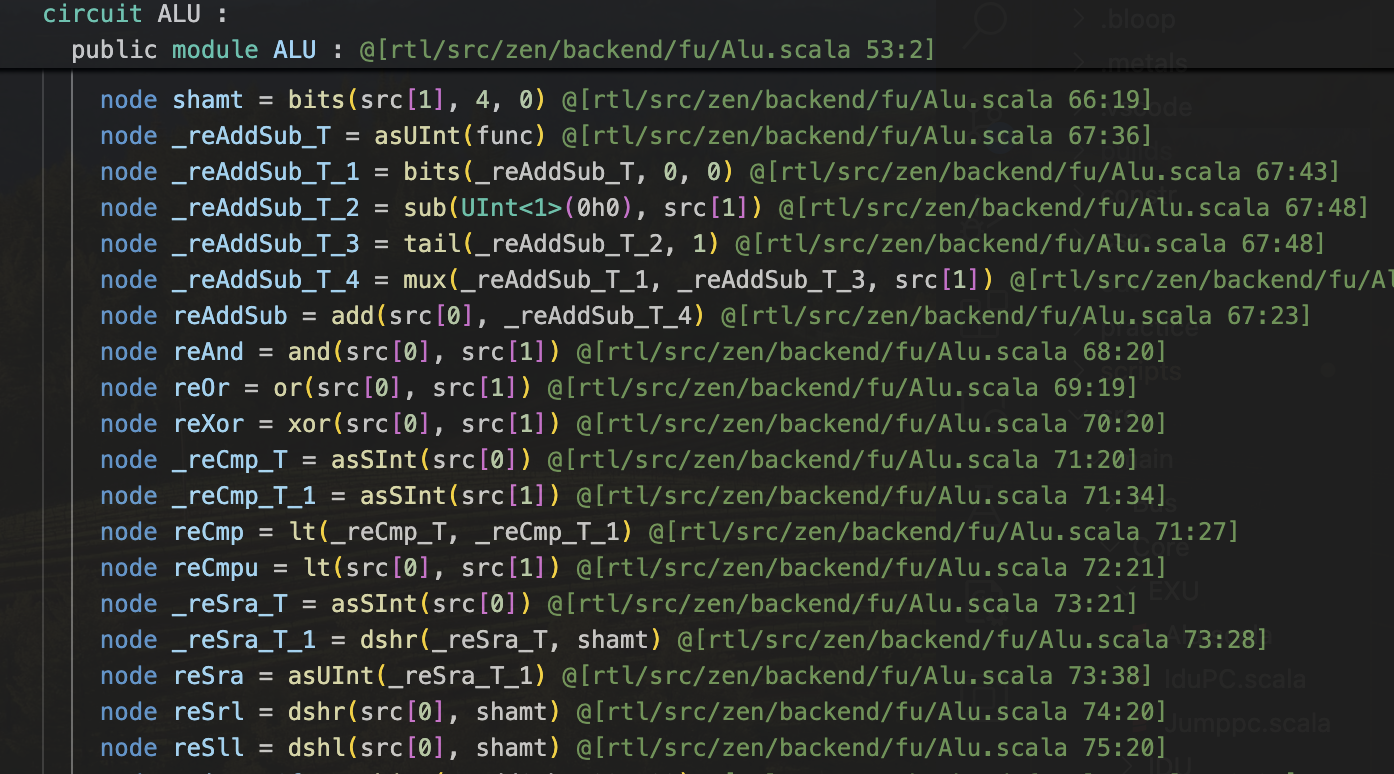
这是一小段alu的firrtl代码,是chisel所有meta-programming展开后的结果,但是会发现他的语义似乎还挺简单的(甚至分析难度比verilog还要低),他将所有的微操作都很漂亮的列举出来了,说实话,我现在希望有一个工具可以可视化这一段firrtl,(如果你想要一个工具,那么很可能就存在这个工具)哇,但是我找了一圈都没找到,大多都过时了
但是这个是真的好分析,我仅仅改掉了一个符号,面积直接到1704.528000
其实在优化之前我需要保证他是对的,所以就需要写tb或者formal验证来验证设计,我打算使用chisel nix的formal写法,但是发现Symbiyosys不支持很多产生的sv语法,难受死了
太难受了,弄了大半天vc formal,倒是可以检测出错误了,但是我始终不知道反例的波形在哪?特别难受,感觉工具太少了,哎…心态有点爆炸,找到了一个fvtrace的命令,但是运行时直接给我卡住了
优化了一波,时序直接从885.670到了1208.797,主要的优化手段就是把加法减法的结果给比较,通过合理编码aluop减少mux的压力,平衡mux(如果把mux看成一颗树,时序作为参数,就是平衡树两边的时序),忽然发现formal测试过不去,但是修改之后时序和面积反而再都优化了一点,(顺便复习一下取反+1,取反,让一个值变成了最大值-这个值,就像陷入一样,但是是以多加一位的视角看是陷入,然后如果加的值大于这个被减数,就会溢出到上一位,就是说3-1会溢出,1-3反而不会溢出)
一些架构上的优化
之后需要优化的模块,似乎都和架构考量有关了,所以我感觉我需要先弄清楚我的架构改怎么优化才能达到最佳,在此之前,我打算把之前的架构弄懂(因为太久没写了。。。)
以前的架构
我之前的架构就是经典的IFU,IDU,EXU,LSU,WBU,然后通过握手信号connect,然后只要io.valid===1,说明这个模块正在忙,IFU的输入是上一个周期的自己输出的pc+4信号(always not taken),然后IFU的输出会连到icache上,icache是一个一周期返回数据的cache,并负责axi通信
然后首先是数据冒险,我的实现特别的丑陋….,是通过将idu,exu,lsu,wbu的数据从模块中拉出来,观察各个模块需要写入的寄存器编号和idu需要读出的寄存器编号进行比较,并通过一些控制信号来判断是否能转发,并且通过mux选出需要转发的数据
之后是控制冒险,真正的pc需要在exu的时候计算出来,我就在把exu的这个信号拉出来,并通过简单的对比是否不等于pc+4来判断是否存在冒险,这个路径是关键路径之一,并且s只判断了pc+4,没有扩展能力,肯定需要重构的
还有一点就是控制信号等太多了,需要尽可能减少在流水线中传播的信号以优化面积
优化的架构
啊,真是一个头疼的问题….
首先我觉得我的ifu应该不会有大改动,假如我面积不够,我肯定没办法实现BPU之类的东西
所以我打算首先写我的IFU
既然要先IFU,那就得先icache,既然涉及到了icache,就不可避免的涉及到了bus,看了nutshell的代码,发现整个核都是用一个叫做simplebus的总线协议交流的,我发现这个其实很合理,如果core直接用axi来与外界通信,就会存在一个问题,对于不同的soc协议,并不是很好适应,并且axi对于核来说太重了,所以我想顺便修改一下bus
移植了一下nutshell的simplebus和一个toaxi的模块,让我评估一下toaxi的模块的面积,看是否在接受范围之内,其实我就只需要在core的最后加这个模块即可,210!,非常不错的面积开销,2702.301MHZ,也非常不错,而且正确性可以有很大的保证,毕竟是从nutshell中迁移过来的,ok,现在我完全不需要考虑axi了,全部用simplebus即可
IFU写完又600多面积,时序1875,感觉还是太多了,最占面积的pc其实应该只占144,估计还是有很多冗余的逻辑,但是在改进之前照例是要写tb或者fpv的,但是这个tb就并不是那么好写了,它存在3次握手(本来是四次的,我一开始优化掉了in的握手),三个握手之间又存在依赖关系,导致很难很好的给激励,以及也很难写SVA(我在chisel写的sva,变成sv之后,竟然产生vcf不支持的语法,哎,不过这种握手还是肉眼看比较好)
在写握手的tb的时候我忽然想到,如果我能把握手的行为抽象出来,抽象成一个class或者函数,然后是不是就可以很方便的测试了,并且我可以写一个chisel函数,一个作为master,一个作为slave,然后只需要在模块中通过合理的组合,就会变得十分优雅,我试试看可不可行,首先是master的握手的spec:valid信号指示着输出数据的有效,在ready为0时,需要保持输出以及输出数据的有效,当ready变为1时,从risingedge开始,需要保持valid持续一个周期,然后下一个周期握手结束,一次传输结束,然后就是下一个周期什么时候开始,我觉得这个需要一个enable信号的传入,就是假设en=0,则强行将valid置0,然后是slave的spec:ready指示着是否能得到数据,然后依然是fire之后置0。但是我发现很难的一点就是握手之间的关系,一个握手很难handle这些关系,还是需要在外部维护一个大状态机管理者三次握手,难道真的做不到吗。。。最终我用了这种方式
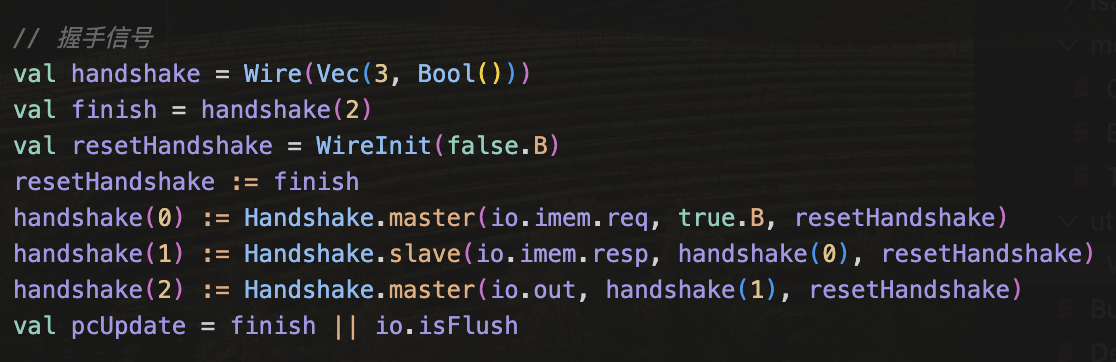
每一个握手通道在handshake内部维护一个寄存器,保存着握手的状态,resethandshake表明着一次循环握手的结束,这样就不用写状态机了,而且我感觉这样可以很好的表现出各个handshake通道之间的关系
通过这种handshake,我重新构造icache,写完同样大小,面积小了不少,当然,我写icache时,还构造了一个叫做MemWithPort的utils,模仿的是chisel.util.SRAM,可以固定住port的数量,这个MemWithPort的基本结构是一个Vec,也就是用set来index的,这里嵌套了很多层Vec,首先是Mem是set index的,每一个单位是一个Vec(way),每一个Vec中的每一个就是一个cacheline,这个cacheline也是一个Vec,每一个是一个word,是由于burst的存在,大小是burst len,所以说一个Mem是一个vec(vec(vec))),分别是由set,way,burst 来index的
idu肯定需要大改,暂时想到几个问题,先列举如下,1,输出的东西太多了,这些东西都要进流水线间寄存器,要爆炸的,所以肯定需要通过一些奇思妙想,把最本质的东西传出去,2,处理数据冒险太粗糙了,是否需要将idu拆开,拆出一个isu来专门维护一个scoreboard来做这件事,但是是否真的需要这么做,还需要考虑面积,但是我肯定会先试试的。3,我的一个奇思妙想,是否将译码中ISA specific的东西拆出去,不管是什么ISA,都提取出最本质的东西,而这些最本质的东西都是相同的,因为我的处理器是相同的,从而实现仅替换译码部分实现处理器的替换(这个东西最本质的问题就是两种isa对我的处理器各部件的要求是否相同,如果都只有运算指令,那他们确实都只需要一个alu,那就可以实现替换)
于是我还是打算像之前一样画一个drawio来表达我的架构,毕竟架构架构,就像建房子一样,还是很需要一个蓝图的
画了一个很简单的版本,就简单的描述了其中的数据流动
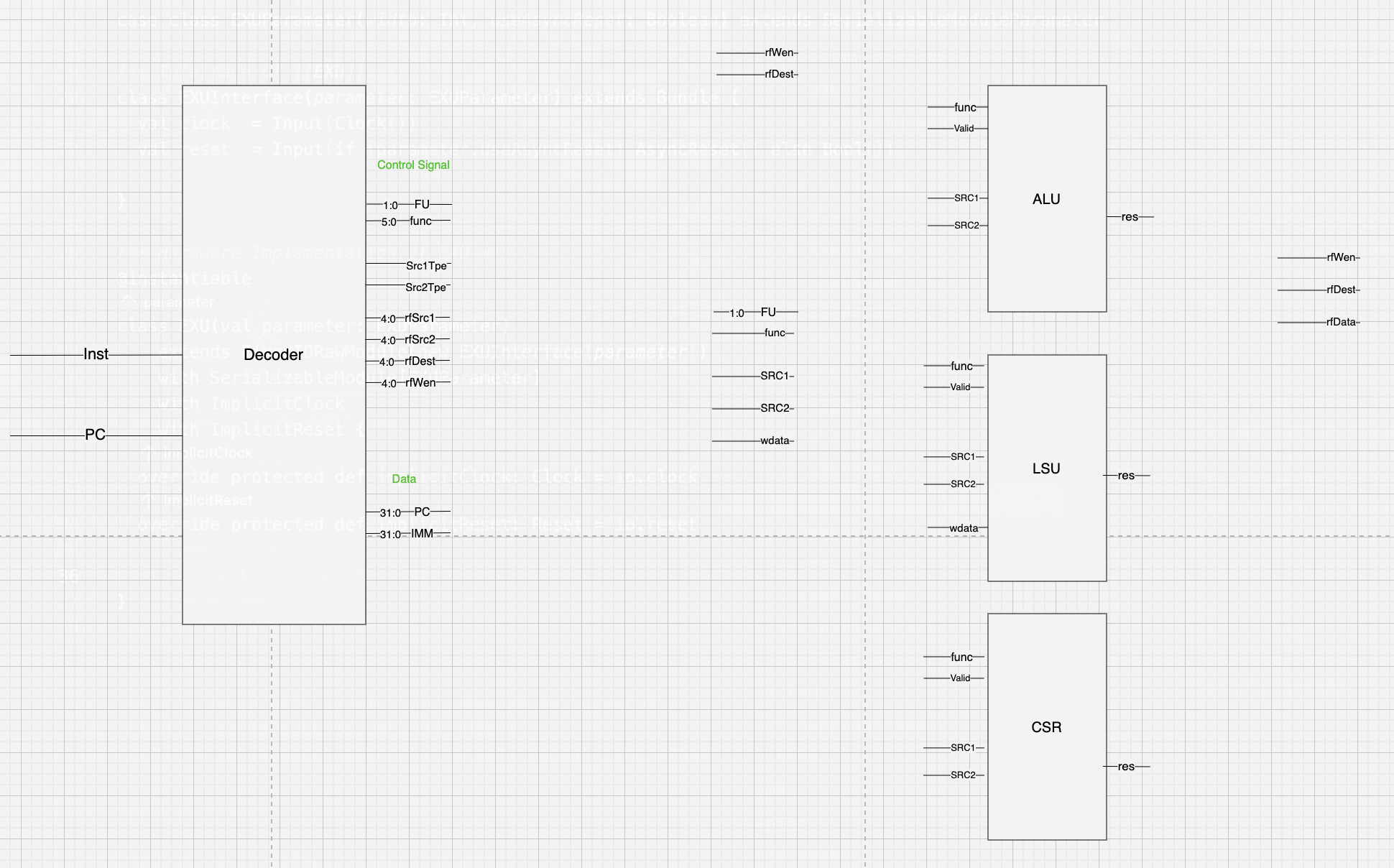
写idu的时候打算用chisel的decoder,其实有一个rvdeocdedb能帮我做一开始的很多工作,但是由于la没有这个东西,我在考虑是否可以不使用这个东西来实现,算了,我打算还是用rvdecodedb来完成我的工作好了,之后la再重写一遍
用rvdecodedb过滤了一下需要的指令,然后打印出来他们的信息
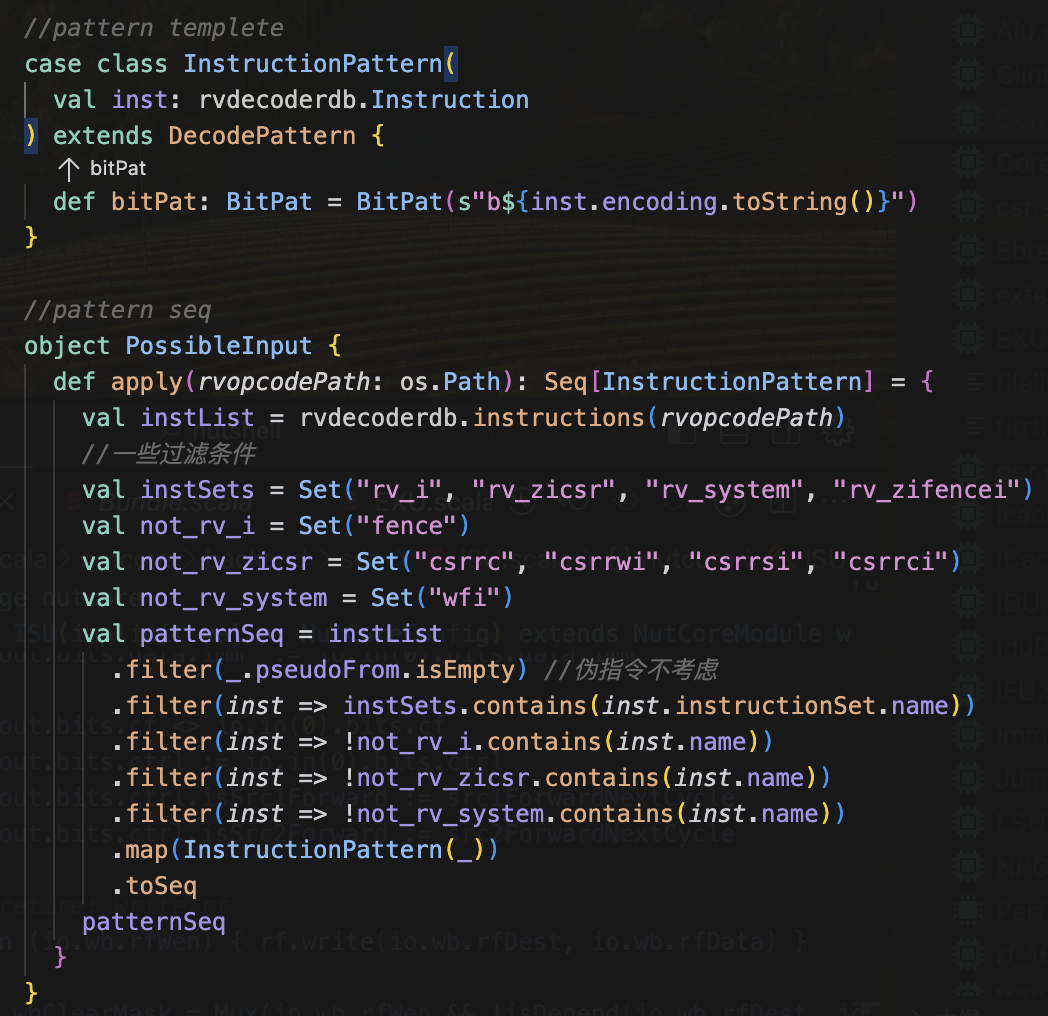
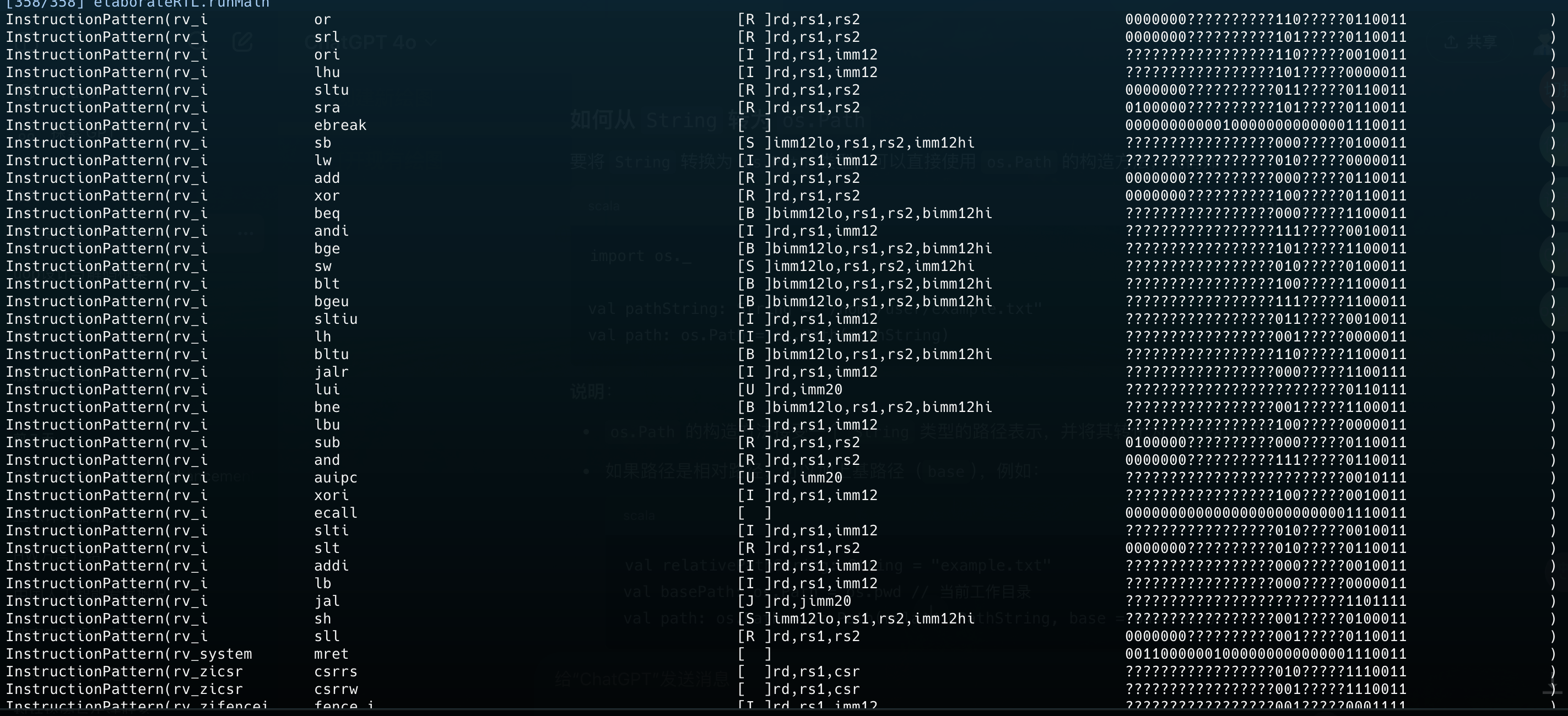
看起来很不错呢
写的时候发现一个巨大的问题,我似乎忘记考虑branch和jump指令了,我把现在需要实现的指令分成了四类(暂时没有考虑fencei,ebreak指令,这两个都需要专门来一个field做译码的,(应该就没有漏掉其他的指令了吧…)
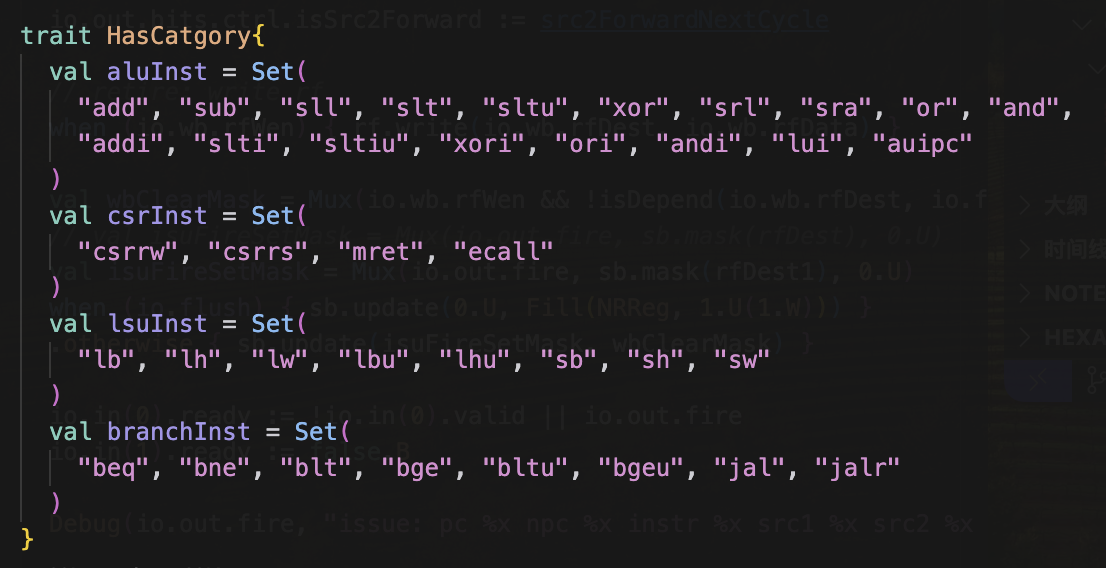
- aluInst都是需要两个src的,并根据func在alu中产生写入rd的值,感觉是最简单的
- csrInst的前两个的src1为csr的编号,src2为某寄存器值,并相应产生rd,和计算指令的形式差不太多,但是后面两个虽然也会分配到csr unit中,但是有些不同,ecall指令接受一个src就是pc,并设置相应的mepc,产生targetpc(mtvec),而mret也同样产生targetpc(mepc),(实际上他们还会做更多的事情,但是在我的处理器中,他们似乎只是一个产生targetpc的东西,这两个指令我的csr unit还没办法handle,插个todo
- lsuInst的指令都需要计算出vaddr,这个需要两个src,同时store指令还需要一个wdata,实际上lsu就需要三个src的口(但是我现在在想,既然vaddr的计算是相同的,我是否能在isu中对这个值进行计算,可以省下32bit的面积,todo)
- branchInst的jump需要两个src,分别是pc和imm,然后产生targetpc,这个可以直接丢给alu,但是br指令有点麻烦,他需要pc+imm计算出targetpc,然后还需要进行rs1和rs2的相关运算,也就是说需要4个src,面积会很大,store指令需要3个src,我可以通过提前计算来减少至2个src,但是4个src提前计算pc+imm,也只能省下一个src,所以总是需要3个src口的,而且需要一个加法器,我打算把这个加法器放在isu里面,叫做addradder,这个addr的一个口是连着imm的,一个口根据是br还是store进行pc和rs1的选择,最后最后产生一个进入exu的addr数据(todo)然后为了支持pc的跳转,需要根据控制信号以及alu的结果进行各器件产生的targetpc进行选择(包括csr的那两个指令产生的,以及addradder产生的)
根据上述,完善架构图如下
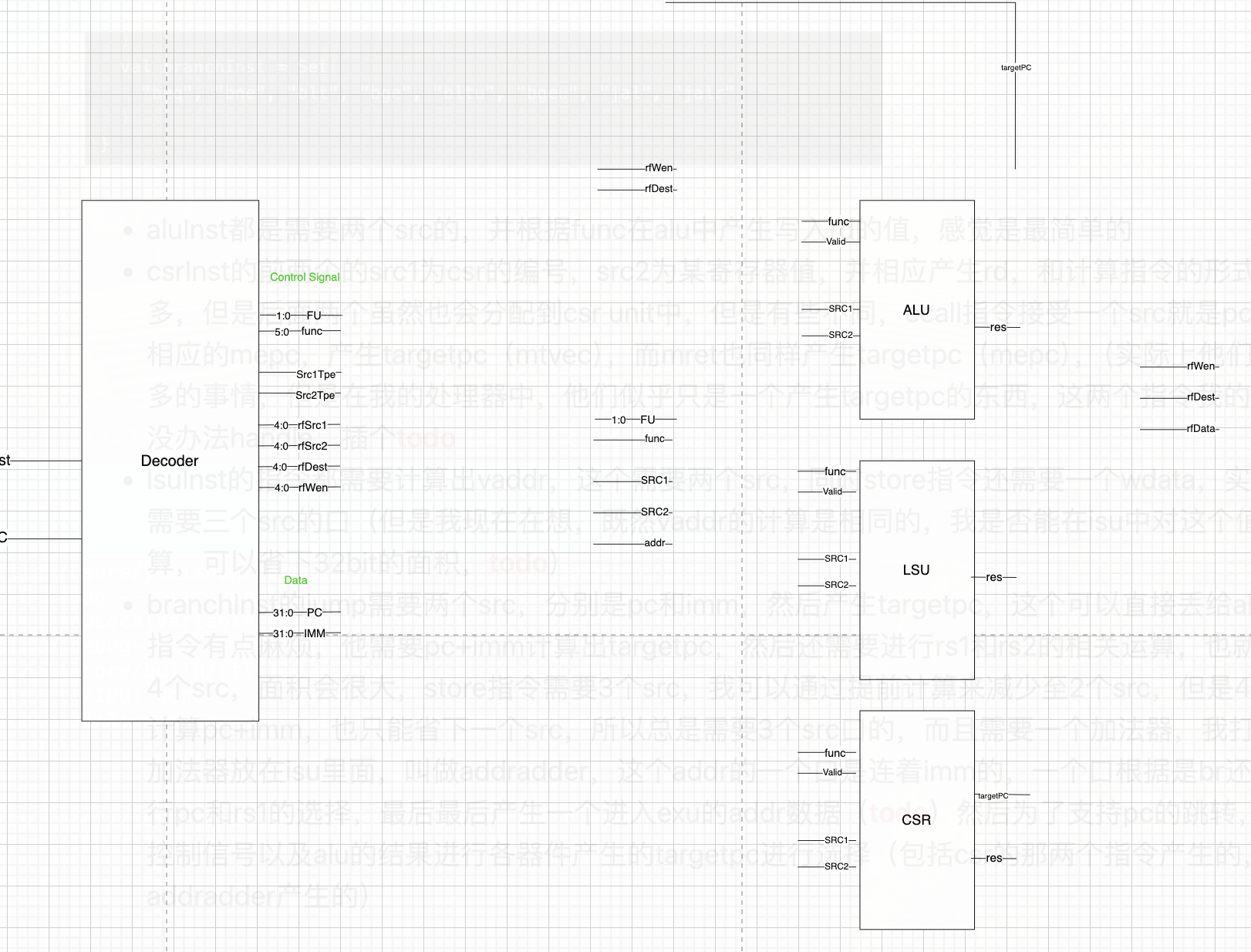
依然还是比较抽象
写decoder的时候报错

但是我始终找不到问题在哪
一气之下改了改chisel的这段代码(让gpt)

打印出
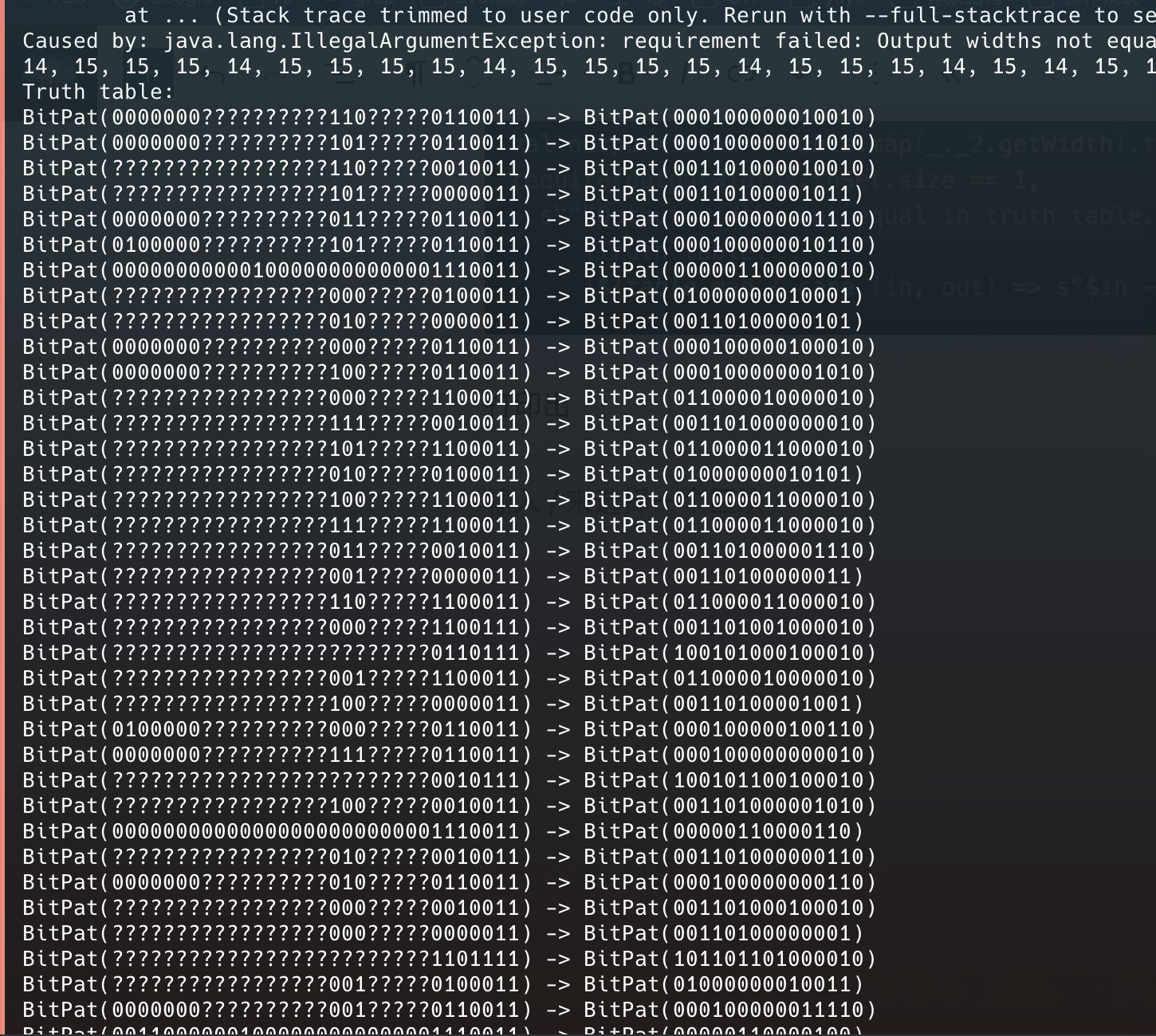
神奇的发现既有15又有14
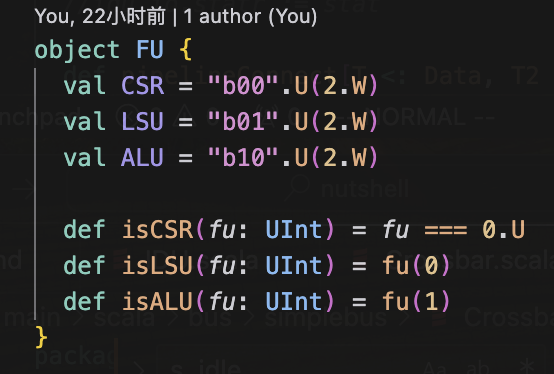
最后发现,我是在这个里面出的问题,没加2.W,然后前两个被默认推断为1.W了,导致宽度不匹配,真粗心呀😭
感觉写过来都挺顺的,我都是在期末周写的,看了一眼面积才2.2W(最担心的流水间寄存器只有2900多,非常不错),当然我还没加xbar和axi的一些东西,但是就算加上我感觉也就2.3W,之后可能有bug,修一些东西,加上一些还没实现的功能(比如ifu可能会产生异常之类的(虽然其实我并不打算实现),还有一些flush没实现完),感觉最多到2.4W了,绰绰有余了((没错,我喜欢半场开香槟
写xbar的时候看了看nutshell的,我本以为写的会通俗易懂,但是我发现有点难读…,我觉得他的xbar写的不太行,但是simplebus的行为毕竟我是抄的(借鉴)的nutshell的,所以我需要知道他的准确行为,当然我觉得他的准确行为应该用自然语言简单描述如下:
我认为的N21:当dmem和imem某一个req的valid为1的时候,选择相应的bus,(如果都为1,我喜欢优先选dmem),然后进入一个work状态中,需要监测req的writeLast或者resp的readLast,如果某一个为1,则断掉所有连接,重新进入空闲状态中
他的N21实现:我感觉写的有点丑,但是是对的,他用了chisel的lockarbiter来做req的arb,来锁req的写请求,在找到chosen之后,用了一个inflightsrc来锁写resp
我认为的12N:首先,在valid时,通过addr选择一个out,然后同样进入work状态中,此时同样监测req的writeLast和resp的readLast来做锁,如果某一个为1,则重新进行选择