
前言:本篇完全是日记性质的文章,想到什么写什么,请谨慎参考(本篇结尾会写出得奖情况,当然,如果没获奖,我就根本不会把这篇文章发出来了(狗头))
emmm,很尴尬,只有三等奖,最主要的理由是时间不够,小瞧了我们的架构的工作量,导致后面的bug没调完,然后由于连bug都每调完,所以性能自然没有调到最优,我写了一篇反思
架构设计
有一个架构来着,到时候放上来TODO(暂定是乱序三发射)
Rename
freelist
参考:https://docs.xiangshan.cc/zh-cn/latest/backend/rename/ , https://docs.boom-core.org/en/latest/sections/rename-stage.html , 超标量处理器设计相关章节, 香山和Boom的相关代码
看了xiangshan的,把他的环形缓冲区指针util抄过来了,感觉挺不错的,然后最近写freelist,之前写了一个FIFO(模仿的是chisel的queue,但是支持多端口),但是确实感觉直接写FIFO并不是很通用,反而是香山的把指针给抽象出来确实是一个很不错的方法,这样写出来就会很简单,然后香山以及我之前的想法都是在freelist里面放空闲的物理寄存器编号,然后维护一个入队指针和一个出队指针的逻辑(我甚至一度以为就只有这一种方式)
但是我看boom是用另外一种方式实现的freelist,就是那种scoreborad的形式(或者说bit-vector),然后allocate时就把相应位置的置1,然后返回这个1的编号,free时同理,为啥我之前从没想到这种方式
让我思考一下两者的优劣,我唯一想到的一点就是回滚的时候,boom需要做checkpoints来恢复,并且需要的checkoint还不少,但是香山的就只需要回滚指针了
感觉香山这个指针抽象真的很好用,非常灵活但是也很便捷,因为有很多地方都是环形缓冲区结构(即FIFO)(然后chisel的queue是通过最后一次是写还是读来判断满或者空,香山是用一个flag,参考:https://zh.wikipedia.org/zh-hans/%E7%92%B0%E5%BD%A2%E7%B7%A9%E8%A1%9D%E5%8D%80,wikipedia上面说chisel的这种方式不适合多线程,这次亲身体会到了,非常不适合超标量,所以我重构了一遍)
之后再看香山代码的时候,发现rob用了多个指针,比如说入队,就用了renamewidth个指针,但是freelist又只用了一个指针,我有点不清楚他们的考量,但是如果是顺序的,我认为就一个指针不就好了,我先按照一个指针的写
吐槽一下:超标量真的麻烦,map,foreach,tabulate。。。一个接着一个,一个套一个,虽然很优雅,但是感觉可读性堪忧
testbench
我提出每个模块,至少要测一下,测的粒度其实可以不是模块级,不过至少是流水线级,即每一个流水线级都要写testbench,确认没问题才能合并到core里面
然后其实我现在是要写rename的tb,不过实际上验证有两种,一种是tb,一种是形式化验证,但是rename写形式化验证感觉有点难,所以打算用tb测(我觉得最好用形式化验证的是那种alu之类的fu模块)
现在准备开始写,但是没有思路,所以在博客里无病呻吟一下,写着写着可能就有思路了
其实我还是一口气就写完了,我这个testbench主要分为两部分,第一部分是激励数据的产生,另一个部分是正确性的检验,实际上,这就是传统uvm验证方法思想,即使用的不是uvm,只是真正的uvm会包含更多,sequencer,genrator…..
最主要的一部分其实是正确性检验,之前写核的时候,大多数都是直接看波形来检验正确性,之后有了更好的定位bug的方式,difftest,于是,这次我也使用cpp写了一个软件模拟的ref model,当激励数据生成后,不仅会丢给dut,而且会同步更新ref,然后在两者中对比结果,可以省下很多看波形的时间(其实我发现在超标量处理器中看波形是一件挺恶心的事情的,因为信号量是原来的三倍(我是暂定三发射))
(检测的时候出现了很多笔误,我估计不是笔误,是cursor的自动补全我没看清就点确定了,哎)
我在想着测rename的commit的时候感觉还是有点复杂,因为我还没来得及实现ROB,嘶,但是我可以用软件实现rob然后仿真出那种效果
然后基本功能实现完了,也测完了,之后很重要的一点就是冲刷和恢复机制的支持了,重命名阶段倒是不需要考虑flush,只需要在需要flush的时候把所有的wen置空就好了,主要是这个恢复,我到底选择哪一种方式恢复,checkpoint,walk,以及用archRAT,我不明白为什么checkpint这么简单的实现方式似乎其他队伍都不实现,而选择walk这些更困难的方式
不过为了一开始不踩坑,我还是用walk的方式实现好了
最后一步就是在vivado中分析时序了,由于我的rename模块是单周期的,所以会导致vivado没有很好的办法对时序进行分析,我把rename的所有io都拉到顶层,但是在impl的时候报错,说io端口太多了,但是我发现其实在综合的时候就可以看时序报告,但是这个时序报告可能并不准确,不过我也没有别的办法了其实,最后我发现关键路径是在读freelist时,此时freelist的大小其实挺大的,有128,但是我换成64之后,发现还变慢了,我:?????
我觉得可能的原因是我是用的reg,所以这部分的读逻辑是并行的,即有128bank,128个读口,但是为啥会变慢我有点不太理解,哎,不管了,之后再优化吧,反正现在来看100MHZ还是有不少余量的
Issue
首先是Allocation,其实我的设计中并没有什么专门的dispatch阶段,从rename出来的数据会很自然的首先和ROB连接并写入ROB,并行进入发射的第一个阶段Allocation,此时会做指令的分类然后对不同RS的写入,这个阶段其实就是传统的dispatch阶段,当然,我在rename后面会加一个流水间寄存器的,所以其实我是把dispatch的逻辑分到了ROB和Allocation两个不同的模块中处理
xiangshan是有一个专门的dispatch模块的,我认为最主要的原因就是RS的写口的问题,香山6发射,以为着可能同时dispatch 6条alu指令,如果alu对应的是一个RS,那这个RS就需要支持6个写口,这是不可接受的,所以它把dispatch中间插入了一个queue,来解耦上下游可能的速度不同问题,但是我是3发射的,所以我是否可以接受RS有3个写口呢?,我认为是可以的
之后确切实现的时候,有一个问题,对于压缩,我不知道怎么用rtl很好的表达出来,实际上发射队列是一个顺序enq,乱序deq的queue,所以其实并没有一个确切的deq指针,而由于是压缩,所以实际上最底下的entry都是valid的,我询问了gpt o3-mini,真的挺聪明的,把FIFO,乱序deq 1 entry FIFO,乱序deq 多entry FIFO的实现都给我表达了出来,但是他是根据原内容直接做一个新的结构,然后用这个新的结构来更新原来的FIFO,🤔,这样难以表达出一个语义,即最多的空洞是fuNum个,这种方式直接重新调整了,有一点点害怕这样的实现会带来一些问题
之后其实有一个想法,就是把能在单周期完成的指令与乘法指令分开,用两个不同的RS(出于时序焦虑),我思考了一下并没有发现可能潜在的性能问题,比如两个alu用两个RS,就可能存在一个RS中有两个指令准备好了,但是一个一个都没准备好,就会损失部分性能,但是如果是alu和mdu分开的话,即使alu中的有两个指令准备好了,也其实不能放在mdu中执行,就不会存在问题,🤔,我感觉大部分的设计中把这两个合并我认为是它们让mdu也有alu的功能,来疯狂压榨mdu的功能,但是我们其实没有面积焦虑只有时序焦虑,所以我认为是可以分开的,分开之后,我alu的RS的单个表项的bit会减少一点,可以缓解时序压力
其实放入RS之前需要能对src的ready位进行正确的置位,但是他们可能一开始并没有获得延迟唤醒的福利,所以,我使用一个scoreboard,记录每一个寄存器的valid和延迟唤醒的时间,也就是说这个scoreboard需要接受三个阶段的读写,1.最开始dispatch的时候,将相应的pdest置0,读出相应的psrc,如果此时psrc是valid的,就直接把这个信息传给RS,如果inflight,就把唤醒时间和唤醒valid传给RS;2.wakeup的时候,读入pdest,delay,然后置位;3.最后writeback的时候,即和物理寄存器更新的同时,更新相应的项;之后还需要恢复的机制(但是我感觉这个应该不复杂,只需要walk的时候把相应的表项置空就好)
之后过了几天没写博客,现在是打算整合一下模块
Backend
之后就是暂时将issue,rename和rob模块整合一下,然后为他们三个写一个testbench,就可以保证发射进入exu中的数据基本正确了
暂时测试了一下,感觉没啥大问题
改pipline的时候发现了一些问题,懒得写思考过程了,但是基本的划分是只在rename之后划一个,然后在regfile read前面划一个,这个时候有两个并行的路径,第一个是allocate,第二个是select+wakeup,他们直到在构造newRS的时候本来都不应该有交集的,然后他们都有可能成为关键路径,但是我忽然发现,如果在此周期wakeup的寄存器中,存在一个寄存器正好可以wakeup正在allocate的某个src寄存器,该怎么办,这会导致两个路径提前相交,恐怕会不好(其实至此都是纸上谈兵,还没测过路径长度的)
让我好好思考一下这个路径,首先deq产生之后(即select得到结果后)—>首先会根据deqIdx进行压缩的计算,得到一个基本的newRS,这段逻辑我认为可能会比较耗时,然后deq产生之后,其实可以并行的去构造newEnqEntry(在没有上面产生的问题之前,其实newEnqEntry只需要allocate+sb部分的延迟),so,如果上面那段长逻辑确实足够耗时的话,似乎上面那个问题确实可以得到解决了,而如果不够耗时,我还可以增加rsDepth来强行对其他路径进行掩盖(前提是在100mhz以内,所以其实我一直在纸上谈兵)
这里会存在两个并行的逻辑,首先allocate+sb同时读取并选择产生基本newEnqEnrty 和 从rsData中读取+select仲裁,第二个是deq来对newEnqEnrty进一步加工 和 deq来对rsData进行压缩
其实我觉得问题不大,deq毕竟不需要依赖任何其他路径,而且allocate+sb一开始可能会耗时更多,所以感觉理论分析问题不大
一回去分析天塌了,在没有降低参数前,lut直接140%,频率也-11(100mhz),在把aluRS的大小改成8,alu数量改成2,lsuRS的大小改成8之后,lut在44%左右,频率在-3.5左右,但是我感觉alu为2是不是不太够,如果是3的话,频率在-4.5左右,频率差不多70mhz吧,关键路径是在仲裁+唤醒,似乎也是可以预料到的,所以我需要进行优化
但是在优化之前我应该把功能修缮一下,比如我需要在其中做regfile的读取流水化,修改为流水化需要知道两个流水级之间的数据交流
ok,其实还差一个功能,也是最重要的一个功能,就是lsuRS的唤醒,这个唤醒不仅需要单独写一个RS,还需要单独写它的wakeup bus,因为它的wakeup需要传递lpv并且还是推测唤醒,也就是在我的设计中,被lsu唤醒的指令都只能在被推断成功之后才离开发射队列,即cache需要给我hit or miss的响应,然后根据它给我的编号去查找,如果此时这条指令已经被issued了,就需要把这个issued置1,此时其实还需要同步的对后面几个流水级中的指令进行选择性的flush
所以普通的RS还需要有这么几项功能
- 需有有一个特殊的wakeup bus,如果是这个bus发出的请求唤醒的指令,在被select之后都不会弹出RS中(通过对lpv的所有位做或操作),只是把issued置1☑️
- 特殊的wakebus导致的wakeup需要对lpv赋值☑️
- 需要接收cache给的pdest指令编号(或者用lpv的最低位判断)以及hit miss的信号,然后如果是hit+issued,就直接清理掉就好,如果是hit+no issued,并把最低位的lpv置0,如果miss+issued,就把srcmatch和srcShift=0,并把issue=0,如果miss+no issued,就把前两个信号置0即可☑️
- 在wb信号来的时候,还需要做一次唤醒☑️
- 似乎每一个src都需要一个lpv但是我现在只有一个☑️
- 需要有lpv的shift逻辑☑️
发射之后的流水级都需要一些新的逻辑
- 需要接收cache的miss信号,并根据lpv的值来选择性的flush掉某些指令
新的lsuRS需要一些新的逻辑
- 被选择之后发送到wakupbus时需要将lpv赋值为正确的值☑️
- 需要有新的选择逻辑,按照store来分组选择✖️(这个被暂时实现为顺序发射)
scoreboard同样需要修改某些逻辑
- 在wb信号来的时候,需要做一个唤醒☑️
- 同样需要接收cache的信号并根据hit/miss的信号对某些have wakeuped的信号重新置0(srcmatch和srcShift置0)☑️
- 需要有lpv的shift逻辑☑️
参观了一下xiangshan的最新版文档,https://docs.xiangshan.cc/projects/design/zh-cn/latest/backend/
我忽然发现可以把regfileRead和旁路连在一起
记录一个TODO:需要实现cache的提醒机制(现在是确定周期)
似乎这个推测唤醒还是有点问题,需要扩展我的功能如下
- 需要能识别出load/store指令,在store指令时,不发出delay信号☑️
- 需要支持n条load指令,这需要我有多个lpv,并且告诉我cacheinfo的时候也需要多条,每个lpv是独立的☑️
- 按照访存那边给我的valid周期来确定是lpv的第几个周期拿到了hit/miss信号,并进行相应的清理☑️
- 需要有flush回发射队列的机制,即所有阶段都需要(实际上是SW窗口需要)
- (选:可能需要多一个replay queue?)
现在基本上就是只剩下flush和replay两个机制了,之后就是等待他们把fu都给我,然后我来统一测试backend了
这两个机制对于所有模块都需要进行实现,首先是flush,基本就两件事情
- 对于存在时序逻辑的部件,当前周期flush信号到来时,需要停止所有的写入逻辑
- 对于握手,需要在当前周期将握手置为无效
单周期的纯组合逻辑并没有flush的概念,所以decoder可以不用管这个信号,rename模块呢,其实也是单周期就可以完成的,所以并不需要第二个,只需要停止所有写入逻辑,但是,我的rename提前实现了replay机制,所以当replay和flush同时到来时,flush我认为不能阻止replay的写入,flush能做的就是阻止普通数据的写入,此时robcommit port可能会尝试更新freelist,release掉一些不需要用的preg,此时flush应不应该阻止呢,让我思考一下,我个人认为,flush信号代表的是流水级的flush,这种rob的信号外接进来的应该由rob自己负责,所以不需要管
到了issue部分,它的flush又存在一些新的问题,根据上面说的流水级的flush,任何外部的飞线我都认为他们不属于我这个流水级,比如wb来的飞线,我认为它是属于wb流水级的,应该在wb流水级中存在flush时将发过来的valid置0,但是现在又存在一个问题,我的flush冲掉的是我的in带来的任何影响,但是此时,我的out却完全和in无关(rs的发射完全是根据rs来做的,和in没关系),这个时候需要阻塞out嘛?我认为是不需要的,所以issue阶段的scheduler的flush首先对于rs,就是阻止enq,当然scheduler阶段还有一个scoreboard,但是这个只要阻止写入就好
之后就是Replay了,其实就是处理器状态的回溯,flush是阻止当前周期的写入,但是replay是对已经写入处理器状态的一种恢复,我的rename是通过walk的方式进行replay的,即每周期,通过rob的三个commit口,发送三条携带信息的walk信息,此时每周期,rob都无法做commit,所有部件(有存储状态的部件)都需要能接收这个信号,来通过这些信息进行状态恢复,我的rat已经有这个机制了,但是似乎freelist还没有实现这个机制,让我看看,freelist☑️,RS☑️,ScoreBoard☑️,regfile,这几个都需要实现这个机制
一开始苦恼regfile如何实现这个机制,因为writeback把数据写入之后,之前的数据就不可得了,但是我忽然发现一件事,假如这个指令被清理了,那regfile中的值根本就不会再被使用了才对,所以我根本不需要对regfile做清理,这也是rename带来的好处(即只需要维护rat即可)
之后我的进度会被stall,因为队友还没有给我fu,我打算用一下之前自己写的alu来进行第一轮测试,最主要的是打算完善我的trace系统,之后可以舒服的debug
我看了一下香山的logutils,感觉还是不太适合我,我想打印出md格式的trace然后舒服的debug,我感觉在统一所有的trace之前,我可以为每一个模块写出它自己的trace,现有的trace是
- issue module 的RS和wakeupbus
- spec RAT
- scoreBoard直接被打印出来
但是对于我的后端,有一些其他的trace会更有用
- ROB信息
- 寄存器状态(要从我的后端中读出寄存器状态,需要做两次寻址,首先对Arch RAT进行寻址,找到对应的物理寄存器之后再去读regfile来读出内容)
但是我认为只根据trace和波形debug还是太蠢了,我现在的Backend已经有了可以接入difftest的能力,可以让difftest来自动化找bug,然后出现bug之后再使用trace和波形来debug
为了移植chiplab的difftest框架,我貌似得读读它的代码,,有点痛苦说实话,它是用cpp写的tb,然后在一个无限循环中不断step,应该是每循环一次clock往前进一步,然后在循环中会调用emu的process,然后调用disstestmaneger的step,最后调用difftest的step,最后通过调用do_instr_commit来commit指令,并且之后还会做compare,然后dpic实际上和它的交互是通过修改其中的状态,就是会和step的逻辑分离
之后我在macos上跑这个chiplab的仿真,记录一下踩的几个坑
- 一开始的编译verilog会有提示说要用c++14以上(当使用veriator高版本时),需要在flag中加-CFALGS -std=c++14
- 之后说找不到头文件,需要正确写出verilator的家目录,最好使用这个VERILATOR_HOME=$(shell verilator –getenv VERILATOR_ROOT)
- 之后我的macos没有loogn的工具链,修改makefile,使用orbstack虚拟机运行交叉编译阶段,
orb zsh -i -c "loongarch32r-linux-gnusf-gcc… 之所以使用zsh -i -c是因为orb的非交互式的shell貌似找不到这个程序(即使设置了PATH)
还是有点寄,之后运行时报错The current platform is not supported,原因是la32r-nemu-interpreter-so没有macos的预编译版本,哎,还是老老实实用虚拟机吧
我发现移植是一件吃力不讨好的事情,不如把自己的设计直接放到它的框架中去
之后我需要知道nemu是在哪里执行指令的,是根据给的bin文件呢,还是等commit的时候执行处理器给的inst,我估计是bin文件,果然是的,感觉就是npc环境的一个升级版,我似乎就是要改变这个ram指针的指向就好,它的ram指针会读如ram.dat数据的,我只要能控制这个文件的内容就好啦,这个文件是通过它的一个convert.c从elf到bin再convert出来的
我貌似直接用–ram指定我写的.dat文件,就可以让nemu执行我定义的程序了,现在的问题就是我的仿真程序(就是给我的Backend提供数据的程序没法读dat文件,我打算直接更改ram指针)他这个ram有点意思,直接用mmap获得4GB的内存,4GB正好还是32位数据能表现的最大的数据,所以她可以直接把内存直接映射进去
之后有个坑,我是在mac中编译的dpi-lib.a会导致找不到符号
貌似可以执行并解决指令了,但是现在还有一个问题,就是需要将gpr的值给testbench,这看似是一个简单的问题,但是在有重命名的处理器中貌似没有那么容易,首先需要根据arch RAT来读出每一个逻辑寄存器对应的物理寄存器,然后去物理寄存器堆中读出其中的值
记录一下某个历史时刻
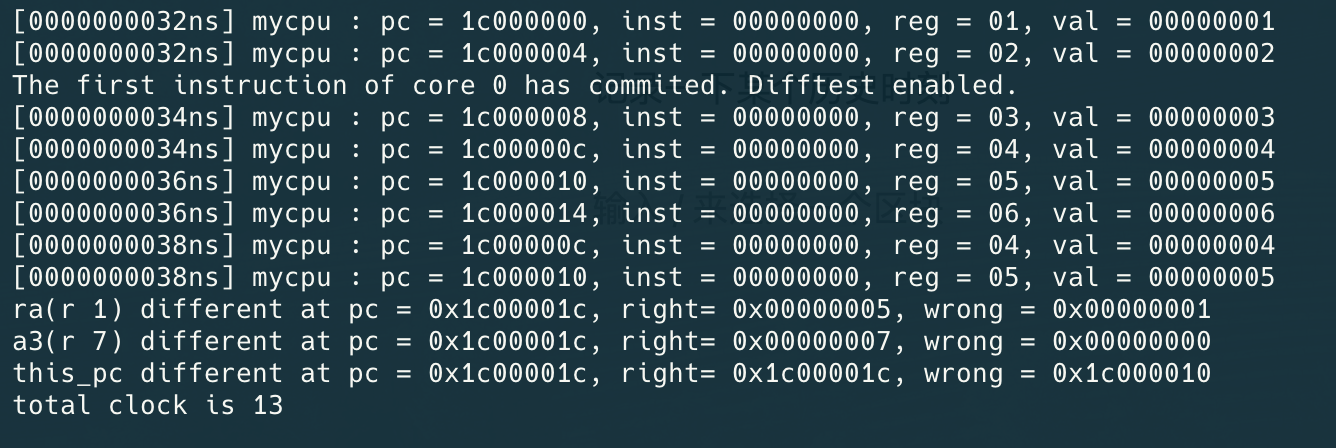
通过了第一条指令,在没有raw并且指令供应完备的情况下可以每次把指令放在两个alu(实际上是n个,只是两个的timing会好一点)中执行,实现双发射,(虽然实际上还是超级超级多的问题,比如这个pc突然回去了,就很诡异
之后就是无聊的debug时间了,debug是一个另人烦躁的过程,你根本就不知道还有多少bug等着你,你也不知道你现在解决这个bug的手段会不会引起一个新的bug,而且一堆不符合预期的行为,只好一步一步来解决吧,相信:机器永远都是对的
时序优化(1)
时序爆了,最大的问题是同一个周期,首先会产生deq信号,这个deq信号会进行wakeup,假如他对当前周期进sb的信号进行wakup,时序就会爆掉,其实本质上,wakeup信号出来的时候,就已经10ns了,就只有12-10=2ns左右的余量了,只是后面那一坨正好也是10ns,就很寄
现在想到了一种解决办法,wakup的产生逻辑基本上是:初始(2.9ns),rsdata中读出是否ready可以被选择(6.975ns),然后丢进selector中进行选择(8.216ns),产生最终的wakupbus(10.893ns),基本还有2ns的余量,可以看出从rsdata中读出的逻辑很耗时,但是之所以把他们放在同一周期,其实本质上是为了单周期的alu可以背靠背执行,像是那种mdu,lsu,他么多周期,在第二个周期做唤醒其实也不是不行,也完全可以做到背靠背执行,只需要少给一个周期就行了,但是alu,假设在第二个周期做唤醒,那就意味着只有第三个周期他才有可能被选出来,就会浪费一个周期,但是我想这个问题是不是其实也是可以被解决的,就是在wakup产生的时候切一个周期,wakup第二个周期给第一个周期,只是,在rsdata中选择ready的时候要考虑这个周期给的wakup的影响就可以了
ok,开始重构:
- 首先分一个流水级,诶,我想,这个流水级貌似可以和datapath合并,就是deq进入的流水级,毕竟其实本质就是把wakupbus给分出去☑️
- 对于多周期的,wakup时要少一个周期☑️
- 对于单周期的,在选择的时候,能考虑wakeupbus的值☑️
- 对于sb,还是用第二周期的wakeup,然后做bypass
之后这一条关键路径确实消失了,现在的关键路径在选择出来之后做压缩,这是我之前认为很难优化的一条路径,但是他-3.1,之后确实想到一个优化方法,就是,其实我判断能不能进队列,是通过enqptr,但是这个信息我并没有使用,于是我打算这样优化:
- 当deq信号出现之后,不马上进行压缩,☑️
- 而只是把一个叫做compress位置1☑️
- 新的周期出现后,完全根据上一个周期给的compress信号做压缩,并且根据这个compress信号和请求数量做判断是否能进队列☑️
- 选择逻辑需要排除掉已经被compress但是没有出队列的entry☑️
然后发现这个compress有点问题,就是当前周期选出了需要deq的index,这个index可能不是下一个周期需要的index,因为会被压缩,需要解决这个compress同步的问题
再来梳理一下,当前周期选出了deq index,使用deq index为某些位标记为了compress,但是,假如下一次没有合理的把之前的comress清空,就会存在问题,现在要不就是把comress放在entry里面,会跟着entry的压缩而压缩,一种是单独拿出来,我感觉单独拿出来性能会好一点,就是把comress每次先置0,然后再通过deq赋值,不太对,假如单独拿出来还是需要对comress进行压缩,也就是说需要deq产生的comress的index不是真正的index,而是需要压缩的index,貌似本质是需要对这个index做处理,还是得和entry放在一起,走那个压缩处理
之后发现把enqptr换成普通的uint还是需要一个flag来指示是否是满的
之后忽然有一种想法,感觉可以提高IPC,就是分3条流水线,而不是一条流水线里面有三条指令,但是我又思考了一下,发现有点不行,rename阶段有一个检测三条指令是否相关的机制,但是又感觉很难受,假如一个RS满掉,意味着其他的RS就算是完全空的,也需要对所有指令进行阻塞,但是由于在进入RS之前,指令都是按照顺序的,假如后面三条,有一条指令是RS满掉的指令,就只能拿没有满掉的指令,然后继续阻塞,并不会提高什么,只是假如后面的指令没有一条会进入RS满掉的指令,就会被生生阻塞掉,诶不对,貌似并不会阻塞,假如下一波进入的指令没有一条进入这个RS,其实canEnq是1,所以问题不大
分支指令
现在需要处理分支指令了,基本上就是三件事,第一个就是alu能告诉我分支的确切信息,第二个就是仿真环境能支持对于分支指令的处理,第三就是其他部件可以做到相应的恢复
开了一个分支指令讨论的issue,我就不把具体的做法先拿上来(毕竟这篇文章只是一个日记)
中途一个小插曲,加了一个difftest的ci,并且加了一条break inst,可以停止仿真环境,具体原理如下:首先decoder阶段decode出是否是break inst,然后在进入rob的时候如果是break inst,就把writeback=1,然后commit的时候如果是break inst,就在下一个周期,调用dpi函数,设置某个全局变量为1,假如监测到这个全局变量为1,函数就会返回end,从而结束,并且break inst不会进入发射队列
之后我发现有一个git命令很神奇,叫做git reflog+git reset –hard的联合使用,可以任意回溯
之后,仿真环境需要实现三个事情,
- 第一个是对于编号的分配,每遇到一个新的分支指令能分配一个新的编号
- 第二个其实是隐含的,就是每次遇到分支指令,都是默认not taken(所以其实并不需要记录什么东西,当然真实环境需要记录下这个分支指令的预测结果)
- 第三个是仿真环境需要接受alu的branchinfo信息,判断它是不是not taken,如果是,就需要发送redirect信号
现在貌似想到一个问题,就是这个编号什么时候回收呢,有的分支指令甚至都走不到commit阶段就被刷掉了,那编号的回收时机是什么呢?我去翻翻书,啊,书上是用的每一个一个编号,然后错误的时候,把当前编号和后面的编号全部回收,我用循环指针也是可以达到相同的效果的,就是直接让指针回到这个错误的编号就好,但是正确的话怎么办呢,让我思考思考,应该就是需要另一个指针,指向队头,然后还需要一个reg,里面存放着是否是已经被verify了,然后这个verify和commit是一个逻辑,只有连着的都verify了,队头指针就可以往前走,所以有两个指针,就可以判断是否是满的了
对于这个编号具体的行为,思考了一下(因为仿真环境需要模拟分支的行为),得出几点
- 首先需要有一个循环指针指向队尾(deqPtr),一个指向队头(enqPtr)☑️
- 【分配】deqPtr就把它的编号分配给每一条指令,如果出现分支指令,deqPtr加相应的数量,并且做分配☑️
- 【回收】【预测错误】,这个时候只需要回溯deqPtr为redirect中给的编号就可以,这样会顺便把这个编号后面的全部回收☑️
- 【回收】【预测正确】,这两个指针需要指向一个verify的reg(Vec),每当出现某个编号预测正确,就把这个verify的相应位值1,然后enqPtr每周期检查包括它在内的连续三个verify是否都是true,如果是,enqPtr可以增加相应连续的个数(这段逻辑和commit一样)☑️
- 【判断满】由于是循环指针有抽象,直接通过enqptr和deqptr来决定是否能再允许新的分支(即是否canDeq)☑️
之后遇到了一些小bug,比如说t0周期rat被写入,t1周期这部分数据送到rob,t1周期此时也有redirect信号到来,必须要等待这部分数据写入rob才能开始walk,还有些小问题但是都解决了,但是我现在其实需要所有fu可以实现精准的flush,不然指令已经被发射出去了,但是又被flush掉了,就很搞,此时需要队友的帮助,但是他们还没回我,我打算先修修其他的bug
之后其实遇到了特别特别多的bug(感谢mantle提供testcase),解决了很大一部分,但是感觉还有很多很多,于是打算开一个大目录记录bugs
bugs
- redirect在datapath中没有正确刷新,需要在redirect的时候关掉相应的outvalid
- redirect在RS的deq时没有正确刷新,需要在redirect的时候关掉相应的outvalid
- 多个redirect背靠背出现时,仿真环境需要判断某些redirect需不需要set new pc
- rename walk的时候条件写错
- rob replay的条件写错,当walkDone的时候,walkStep=0的时候依然还会walk一个之前被walk的entry,但是有的时候walkStep是0的时候依然需要walk掉最后一个,取决于上一次有没有walk掉这个,所以其实我两个情况都考虑过
- lu12i实现错误,他其实是没有src1的,所以他应该src1不能是rs1,但是这会让alu很难写,所以把lu12i喝pcadd这两个指令的src1都变成rs(0)
- 由于specRAT和archRAT对应的regfile相同,所以当同一个物理寄存器在两个RAT中映射的逻辑寄存器不同,并且有对这个物理寄存器的写入,就会过不了difftest,暂时没有想到解决的办法(但是之后发现并不是这个问题),之后发现并不会有这个问题,因为只有archRAT要更新的时候才会进入freelist
- 由于rob的enqptr指向的是最大的空位置,walk的时候会错误的walk这个空白entry,需要加一个valid检测
- RAT在walk的时候要判断walk的指令需不需要更新RAT,就是他的rfwen===1和pdest=/=0
时序优化(2)
现在是分支指令实现之后,时序又变成-2了,我调低了所有为128的参数,全部调成64了,然后跑综合,一些关键路径消失了,但是还是有关键路径的延迟是-2
修了一些写法,然后想把commit信号产生到发送加一个reg切一下,因为commit本身产生就需要很久,并且这个commit信号需要发送给很多器件,所以感觉需要切一下
之后有一个关键路径,只有-0.7左右,是freelist的分配,一个多口的FIFO,到rat最终的更新,这个路径很麻烦,他关系于rename是否能在一个周期内完成,所以做切分可能是一个不好的选择,那就只能硬着头皮去优化,从freelist读出数据用了4ns的时间
这个部分很适合分bank,但是这个任务倒是不着急(谁知道分bank了会有多少新的bug引入)
其他指令
由于dcache时时没写出来,所以打算先想想其他指令的方案,这部分其实是我很不熟悉的,所以我打算先看看手册
首先是特权指令,特权集分为plv0和plv3,所有的特权指令除了cacop都是只能在plv0访问的
特权指令首先是csr的三个操作指令,感觉和rv很相似,没什么好说的
然后是一个操作cache的指令,cacop,emmm这个指令实际的操作是通过里面的一个code指示的,这部分应该是罗师傅考虑的,我应该需要把这个指令传给cache就好
然后是五条操作tlb的指令,我忽然忘记tlb的工作原理了说实话…
然后是两条其他指令,一个是eret,是一条跳转指令,和rv的也很相似,还有一条奇怪的idle指令
后面三章,就是讲的la的地址,例外,csr
MMU
mmu的三种类型
csr.crmd控制mmu是处于直接地址翻译模式还是映射地址翻译模式,前者就是直接虚拟地址等于物理地址
后者又分为两个模式,一个叫做直接映射,一个叫做页表映射,这个直接映射和上面的直接映射不太一样,他是只有两个窗口的地址是直接映射的,就是当访问某个地址的时候,发现他处于某个窗口中,并且权限符合,才会直接映射,而上面的直接映射是指cpu本身处在直接映射的状态,所有地址都直接映射
存储访问类型(cache?uncache?)
然后有一个存储访问类型,感觉其实就是cache和uncache的区别,并且后者要保证顺序,用页表映射时,通过页表中的MAT来得知类型,在处于直接地址翻译,就根据CSR.CRMD来确定类型,如果是直接地址映射,就根据窗口的csr中的MAT域确定
tlb
然后就是经典tlb,但是使用的双页,即一个entry存储一对页数,然后有一个entry的规范,tlb其实本质上就是页表的缓存
但是la32r不需要自己做page table walk,就是tlb只要没有hit,就触发例外,然后硬件进入直接地址翻译模式,交由软件来做ptw
手册之后有一个伪代码来总结了tlb的查找过程,总之就是找不到就求助软件就对了hhhh
Exception
分为interrupt和exception
中断
首先是中断,分为四种中断,核间,定时器,硬中断,软中断,并且将中断信息记录在csr.estat.is中
然后中断需要在硬件中转化一次,变成和普通例外相同的处理过程,比如可以标记在某个指令上面
并且还有一堆中断使能,最终发现需要处理的中断,并转化并标记到一条指令(这条指令必须要是能执行的,而不会被刷掉)上面,变成一个中断例外,走例外的流程
例外
例外首先需要例外入口,除了tlb例外,其他的都是相同的入口,既然是相同的入口,那例外类型就由estat寄存器标识
然后有一个例外优先级,就是一条指令触发多种例外,如何处理的问题
然后就是通用的例外处理过程,这部分直接去看手册吧,感觉和rv的也大差不差了
我在想例外的过程能不能和跳转过程合并一下,他比跳转过程就多了一个csr更新的过程,不过感觉csr这个东西也麻烦,他没有重命名机制,所以他的更新需要小心,他的恢复会更加困难
CSR
没什么好说的了
看完所有手册,我对CPU的存在和目的产生了疑问,cpu确实就是只是指令执行的机器,但是貌似又没有那么简单,他有部分和软件结合的很紧密,还是先不想那么多好了
之后轮到我来实现csr了,但是发现csr需要实现为栅栏指令
思考了一阵,现在基本得出的执行流程是
- decode阶段,对于所有csr指令都fu为csr,func设置正确,并添加一个新的控制信号,叫做fence,这个信号对于csrrd没有用,主要是那些会更改csr指令的会携带
- 当这个带有fence的指令进入rob的时候,就阻塞后面所有指令,但是这里会有一个问题,就是这个指令不一定是三条指令的最后一条,假如是第一条,那二三条就也进rob了,但是如果invalid他们,那就会导致这两条指令凭空消失,思考一下,感觉可以在后端从ibuf中取指令的时候就简单的根据inst(26)筛选一下,确保csr相关指令能在最后一条
- 当存在fence的指令到最后一条的时候,他必然也是没有wb的,所以rob commit的时候检测到这种指令,就去把它丢进csr fu,当他变成wb的时候才会把他commit,此时没有fence指令了,流水线开始正常运转
ok,csr指令完成,现在就是异常处理了,异常处理我还是决定走分支的那一条数据路径,伴随着一些csr寄存器的更改
就是rob的每一个entry都标记一个exception的ecode,然后当commit到这条指令的时候发现它ecode不等于NONE,就打包一个exception的handler发送给csr,csr就做各种csr寄存器的改变,然后发送branchinfo,前端处理并发送redirect,然后就是和分支相同的处理,只是和分支不同的是会把这条产生异常的指令也一起刷掉,诶,但是不对,假如是syscall,那这条指令就不能被刷掉,反而需要被commit
所以syscall的行文很难和nemu对齐,让我分析一下,假如t0,syscall是最老的指令,在t0给csr发信息,csr在t0产生branchinfo,t1产生redirect,并且t1所有csr寄存器就已经改变了,假如t1进行syscall的提交,由于我之前做的reg,所以t2周期nemu才会改变,这样就不对齐了,假设t0,syscall提交,那t1nemu改变,貌似就对齐了,我尝试一下
发现一个问题,就是我之前为了时序好看,就让commit慢了一个周期,所以貌似需要延迟一周期,当t0,syscall是最老的指令,就t1发csr,t2产生redirect,t0 commit,t1真正commit,t2改变
感觉没问题,成功过difftest了,之后需要实现一下ertn
我感觉ertn的实现完全可以当作普通的分支指令来实现
之后还发现syscall 0x11会让仿真环境停止,那我就不用我的break指令了,我顺便把break指令也实现了,break指令和syscall指令是完全相同的实现手法
然后他的那个difftest的excpt我一直没懂是怎么做diff的,很奇怪,我想是不是syscall这种指令不需要他的这个diff,思考一下,假如某一条指令有异常,除了syscall和break指令,其他指令都是不能被提交的,这是他们两个和其他的最本质的区别
啊我悟了,他是当你有发了一个异常之后,后面commit的那条指令需要是异常入口就行,像syscall这种就不行,那我就不diff syscall(这个东西其实不需要做异常diff)
现在的普通的异常处理就是当发现异常之后(指异常指令为最老指令),t0会有一周期发送excptionHandle去csr中进入处理,产生branchinfo以及csr寄存器的改变(这个改变貌似会有点提前,所以要在t1周期就发送excp给nemu),t1周期rob进入excption状态,这个状态无法commit指令但是可以enq,他现在是在等待redirect过来,当redirect过来了,就进入walk状态,把所有指令全部清空,从异常入口开始取指令执行
syscall和普通的不同的地方在于他会在t0周期把自己commit掉,然后后面就没有不同的了
我忽然忘记exceptionHandle会延迟一个周期了,所以真正寄存器的改变会在t3周期,所以需要延迟两个周期
在de一个bug的时候突然对于流水线握手有了一个新的认知
假设现在有一个模块发out,一个模块接受in,前一个模块的out fire和这个模块的in fire有本质的不同,按照时间顺序来说,首先in发射ready,前一个模块看到了这个ready,把valid置1,把数据1发送出去,然后如果是valid,那数据就是也会被发出去(否则就只是采样valid),然后后一个模块在下一个周期接收到这个数据1以及valid,然后可能过了几个周期才ready,此时出现ready fire,就是说这两个fire不是同步的,我说这些话是给我未来听的,然后我现在心里想的是rob和rename阶段,rob的ready作为rename更新状态的使能,两个模块都有判断fire的动作,但是一定不能把他们想同步,这是最重要的,很多时候就容易想同步然后被自己绕进去,比如rename是用out fire来发送allocResp,rob是用in fire来更新rob,但是两者首先就不是同一个fire,后者要慢一个世界,然后主要是rob有一个redirect的时候强行入队的操作,这个最主要的是rename的数据已经发过来了,也就是在第二个世界,但是可能这个时候RS不置ready,此时这个数据就会丢失,所以rob就会强行拿这些数据,但是假如是rob本身不置ready呢,这里绝壁有bug,我描述一下,就是rob本身满掉,但是此时由于上一次的ready,有valid的指令进入了第二世界,这时就会出问题,解决办法貌似是rob要留几个空隙给几个做不时之需(现在主要就是rob没有满过,就没有遇到过这个bug)
啊这个bug真的遇到了,而且我有点不知道怎么解决,捋一下,首先,只要in fire,那肯定此时rob做enq,假设没有in fire,并且redirect了,那我就把一个标志位在下一周置1(寄存器),然后下一周期如果发现这个标志并且enq有东西,那就先walk enq的东西,然后把这个标志置0,然后走普通的walk
之后walk完,实际上那些enq依然还在,因为还没有用ready来接收他们,之前的逻辑是redirect就立马接收所以没有这个问题,现在需要用一个ready来接收他们,但是这个ready RS和Rob都不能做enq
设计空间探索
最主要的就是要探索出一套最完美的参数,ipc要最高,时序要最好,面积要最低,我感觉后面还会有几次这样的探索
第一件事就是做出一堆性能计数器,但是性能计数器怎么表达出来呢,我就先计算一个,就是rob满掉的次数的性能计数器,然后打算去看看香山是怎么写性能计数器的
然后打算把xiangshan的那一套全部移植过来嘿嘿
首先它主要是有一个LogUtils,里面有一个全局的XSLog的object,里面最主要的是有三个全局List,一个是logInfos,callBacks,logModules,最后一个我还没完全弄懂他的用法
第一个logInfos记录了一条log的各种信息,比如说打印的cond,fmt,data,等等,每次apply的时候就加一条,然后他里面通过tapInfos这个方法,底层调用boringUtils,把所有当前的cond和data拿出来
然后callBacks其实和logInfos差不多,有注册函数,调用函数,最后会保存所有回调函数
最后有一个关键的collect方法,这个方法会例化一个LogPerfEndpoint模块,在这个模块里面,他把所有回调函数调用,把所有logInfos打印,并且还有io口来进行控制
之后每一个perf都有不同的功能,但是每一个最基本的都是collect,但是这个的collect并不是直接打印,而是注册到主collect然后添加到logInfos里面,最后再打印,相当于子collect
之后发现用instantial会用不了boringUtils不知道为啥,最终全部改成Module了
然后我暂时不想完全替换掉之前的日志模式,之前的日志模式是用md来打印各个entry,对我现在还是很有用的,所以我就暂时只使用他的Perf模式
之后就要开始思考有什么好的性能计数器去添加的了
我最主要的是关心ipc,频率,面积,当然最主要的是ipc,但是在ipc之前,要保证面积是可以接受的,现在面积最麻烦的地方是在rob,所以我打算先加rob的性能计数器,砍掉一些rob的面积,所以第一个加的应该就是rob的项什么时候会是满掉的,然后计算出他的频率,然后最主要的还是rob最高频率是在第多少个entry
发现rob并没有超过32项的情况,然后rob用了8的情况是最多的,那我就可以无痛把rob调到32了
我打算做一个文档,记录我每一次改变导致的ipc的变化,然后我的benchmark其实是功能测试代码hhh
调到32之后ipc甚至还提高了hhh
第二个下手的是freelist
之后我感觉假如后端一直在发射指令执行那就不会遇到什么问题,但是我之前是对于datapath是没有停止逻辑的,现在由于一些原因,某些指令可能卡在datapath很多周期,导致性能下降,所以之后的性能计数器应该是在datapath,打算再看一遍ysyx的讲义hhh,嗯,真是醍醐灌顶
首先我应该确定性能事件,然后通过性能事件出现的时间占比来进行更精准的优化,按照讲义中说的就是Amdahl’s law
首先从decoder中开始,存在的一些事件有(可以发现decoder并没有什么可能会失败的事件):
- decoder接收到一条指令
- decoder译码出了一条alu/csr/乘法/除法/访存/branch指令
rename开始,存在的一些基本事件有
- rename成功一条指令
- 由于rename模块内部重命名失败,比如freelist空掉了
rob
- rob entry使用的数量的频率
- rob commit
- rob walk
- rob exception
- rob fence指令存在
- rob满掉从而不允许enq,堵塞rename
- rob enq
RS
- RS enq
- RS满掉从而不允许enq
- RS entry使用数量的频率
- RS deq
- RS cannot deq(由于RS的原因)(这个很重要)
dataPath
- 指令等待
exu
- alu/csr/mdu/lsu执行时间
wb
- wb
我发现perCount的utils还有专门为队列打造的的,除了XSPerfRolling,其他几个都是非常有用呀感觉
之后出现一个bug,当walk的时候,如果指令中存在waw相关性,打比方,1和3都要写进6,然后1被分配了60,3被分配了63,那3的old_pdest就会是60,然后之后walk的时候他们被同时walk了,那1和3都会把oldPest写进6这个坑来还原,假如是1先写,3再写,就会变成60,这很明显是不对的,如果是3先写,1再写,那就是没问题的,之前其实都是没问题的,因为回溯的时候是用enqPtr往回,但是假如是把enq的数据退回去,那顺序正好就反掉了,很细很细的错误,如果之前没有这个问题,我甚至都不会考虑walk的时候的waw相关性
之后花了一整天加XSAssert,最难的技术就是需要在assert之后能把信息都打印完再assert,直观的想法是延迟几个周期再assert,但是这又会带来一个问题,就是如果这个assert在when里面,并且在某一周期assert条件触发之后,后面when都没有成立,就会一直没法assert,Emin大佬跟我说用AssertPropery,但是verilator不支持|=>,所以其实也行不通(这里还一直遇到了一个问题,后面发现是firtool的版本太低了),最后拿外卖的路上忽然想到为啥不用dpi来做,就是加一个DpiAssert,让仿真环境延迟几个周期然后退出,之前一直局限在chisel也就是rtl里面,差点忘记还有一股神秘力量—dpi-c
调了一下参数之后又报错,跳了,最后发现错误,得出用CircularQueuePtr的时候最好不用用类似deqPtr.value+1.u,而是(deqPtr+1.U).value
我发现调参数很容易触发bug,调了一下又触发bug了,是一个redirect刷datapath的问题,比方说datapath的alu有三个,但是握手逻辑是这三个为一组,但是假如reidrect刷的时候正好只刷一个指令呢,我现在的逻辑竟然是假如有一个在waiting data的时候就不刷,这个刷其实是置inready的过程,在redirect的时候强行reset掉我的handshake,但是并不会强制inready,是因为存在某些不会刷掉的指令,如果不分开握手的话,貌似唯一的办法就是在redirect的时候把一些deq的entry的valid置空
把性能计数器大多都调好了,之后先优化一波时序
时序优化(3)
首先修了一些完全用不着的逻辑,比如说在scoreBoard对于flight的bypass
然后之后有一个有意思的东西,我有一个关键路径在select中,我有一个判断是不是这个指令要使用rs1,有两个例外情况,我如果把这个判断放在关键路径里就会很难受,但是这个逻辑完全可以丢到decoder去做,其实也不必要那么早做这个判断,可以enq RS的时候做这个判断
上面那条路径太难优化了,先降低到原来的参数
之后又是freelist那条路径,之前想的办法是分bank,但是忽然一拍脑袋,发现根本不需要分bank,他路径上是需要满足一个条件,才去从freelist里面读值,但是我完全可以提前把值读出来,而不依赖那个条件,一下子这个关键路径就消失了
之后有一个关键路径是在alu bypass里面,他bypass过来之后发现还需要经历一个32位的加法,就会很长,我只需要把这个加法放到alu里面去做就没问题了,代价是面积多了一丝丝
之后又有一个很烦的关键路径,就是dataPath ready的时候,才会告知RS可以update了,这个时候RS才会把有compress记号的entry compress,这一条路我做了两个优化,第一个是在RS中,把compress的逻辑置到最后最后,才依赖这个ready来做update,第二个是在ready逻辑产生中,也是提前把之前RS的dependOnRs1直接传给dataPath,并且把waitingdata1和3合并,因为他们两个本身就是代表的同一个意思
之后又出现一个在RS中的关键路径,但是我没有看懂这条关键路径,我甚至都不知道他这一条的逻辑是个什么??他最后的写入是我rsData的delay寄存器,我先看看我代码中哪里有对这个寄存器的写入,delay寄存器的作用首先是记录当前指令在exu中的执行周期,然后第一个写入的地方是enq的时候对fu的判断,来写入相应的delay,但是我神奇的发现,我对delay的写入只有这里,我:???我有点懵,这个关键路径在哪?
不对,貌似这只是表象,我在构造newRsData的时候会将所有的东西全部重新写入,里面唯一的变数就是compress和enq,enq感觉问题不大,主要是这个compress,但是他这全是什么brIdx什么的,我很迷呀,brIdx参与的唯一计算就是用他来生成要flush的entry,我还是打算先暂时不优化这一坨了
仿真LSU
由于dcache时时出不来,tlb又是遥遥无期,所以打算先写一个简单的仿真程序
但是感觉写一个仿真的tlb还不如直接写tlb,但是感觉可以先简单的写一个访存的dpi函数,暂时和alu相同的,一周期返回数据
但是我发现仿真lsu不能立马对数据进行写入,只能在commit的时候写入,但是又存在一个问题,就是后面的load指令需要这个数据怎么办
ok,成功过了测试
之后尝试在过syscall测试的时候发现需要它提供的异常处理代码,所以把测试迁移到chiplab了
之后debug又发现了一个之前发现过的问题,就是当后一个模块的ready为1但是前一个模块持续发no valid的时候,只有这个valid会被传过去,所有的其他的bits都没有办法传过去,所以一旦有东西依赖了比如说bits里面的各个valid,就会出错
然后我发现这个错误基本上全是试错出来的,就意味着只要有这个bug的地方全是被跑出来了,所以其实我再去看的时候发现基本都修完了
MMU
为了加快进度,还是由我来写tlb吧,我看openla500的tlb写的特别简单,感觉估计不会很难
我在想tlb需要几个周期呢?怎么分流水线呢?
我决定还是就是addr给进来,得到pa之后丢到寄存器中,给外界就是这个寄存器的值,诶不对,假如是用sram的话,读还需要一个周期,所以意味着,时序需要这样划分,2 stage,stage1就是发送读请求给sram,stage2进行tag比较,然后我看一下他的那些指令,感觉问题不大
有点头疼,我现在tlb指令有部分指令需要两周期执行,那些tlb write指令都只需要一周期就可,两周期意味着我有点不知道把他们放在哪个RS里面,如果放在alu里面会不会出问题呢?是会的,考虑第一周期三条指令有一条是tlb指令,第二周期全alu指令,则第二周期会存在4条已经执行完的指令,但是writeBackPort明显只有3个
但是如果是read相关的tlb指令,可能都需要改变csr,所以可能需要当成bar做处理,这意味着一条两周期完成的tlb read指令并不会出问题,但是我忽然又发现!所有的tlb指令都没有对rd的写入,这意味着实际上我完全可以把所有tlb指令一周期执行结束,反正他们也没有对rd的写入,但是由于tlb本身端口的限制,或许一周期并不允许两条
现在基本上是三件事,一件一件来吧
- decoder添加tlb指令,并把相应tlb指令当作fence
- RS不能一周期发送两条tlb写指令
- mmu添加所有指令的支持
先做第一件事
发现其实tlb指令性能啥的都无所谓其实,那我就把这些指令全部当bar处理,这样强制保证了每次只有一条tlb指令,这样就不需要改RS了其实
写这部分代码的时候,代码行数终于破万了
tlb过测试了
之后打算过异常和中断测试,需要往csr模块里面加内容,然后感觉csr非常混乱,各种逻辑堆叠在一起,我打算使用一些方式做一些简单的处理,比如把相关的逻辑放在一起
首先查看模块内容,发现主要分为几个逻辑块,首先是各种定义,啊没写完但是代码写完了,那我就不写了
之后可以模拟成功,并且通过TEST7
我在想我能不能在实现原子访存llw和scw的时候乱序发射他们,反正scw要是先被发射也只是这次访存失败,我感觉功能上估计是没啥问题的,但是估计过不了difftest
这个idle卡了我好久,我之前被nemu误导了,处理器不应该把idle实现成无限循环的,无限循环很麻烦,应该让rob变为idle state,然后不ready,然后只有当ti的时候,再ready,rob真的是处理器的心脏呀,rob是我唯一写状态机的地方,有walk,exception,normal,以及现在的idle状态,都是整个处理器的状态,而不仅仅是rob的状态,这很有意思呀感觉
推测唤醒
之前其实写过这部分,用lpv来标识load指令的位置,但是发现其实lsu给cache信息的时间实在是不确定,所以我打算就用一个lpv一位来标识这个指令,但是我发现好像有点问题,就是不知道这个来的cache info和哪些指令有关联,诶,我想想用寄存器编号可以吗
我想想整个流程,首先就是load指令被唤醒,出队,这个时候把他自己和有所被唤醒的指令都置上lpv标志,然后之后有lpv的指令唤醒其他的指令都置上lpv标志,有lpv指令的指令不会被compress,然后当哪些有lpv的指令,比如说一条add指令被唤醒出队,进入datapath,此时最好的情况是获得cacheinfo,说hit了,并从bypass中得到数据,否则,他就因为waitingData被卡在了datapath,如果他是有lpv标志的,那么他实际上是在等待cache miss的结果,如果cache miss,他就会被刷回RS里面,至于如何判断这个cache miss是不是和这条lpv指令有关,就通过cache的pdest和当前指令的psrc来判断,因为由于重命名的红利,所有的pdest都是唯一的,所以就没问题,所以本质上就是在miss的时候能减少在datapath中停留的时间,所以一个在进入datapath的指令,有三个去处,1,呆在里面。2,得到bypass数据或者寄存器数据出去。3,得到cache Miss的消息,然后刷回去。所以每周期,都需要检查很多地方,scoreboard,bypass,cacheinfo,然后RS就是得到cacheinfo,是hit就compress,是miss就把issued置0,然后wakeup置0,lpv置0
我这个想法好像有点问题,我貌似没有很好的考虑间接唤醒的指令的情况,比如说一条指令的src是load的dest,但是这条指令又唤醒了一个普通的指令,此时,这个被唤醒的指令的src和dest和那条load指令完全没有关系,所以这个时候如果出现一个这个load的cache miss的信息,这条指令并不会管这个信息,所以这个行为是错误的,所以现在的问题其实就是在说如何让间接唤醒的指令能和那条load指令产生关系,一个非常简单的办法就是给load指令编号,或者说直接使用load指令的robidx配上一个一位的lpv,然后一直将这个信息不断的传下去,似乎很完美,比寄存器对比应该要快一点,毕竟寄存器又64个,robentry就32个,5位比较,每一个rsentry就携带6位信息,比之前的lpv要小不少了,诶不对,robIdx是robPtr类型的,还有一个flag,就是7位
诶我在想这么一个情况,如果一条load指令直接或者间接的唤醒了一条普通的load指令,那这条load指令再唤醒其他的指令,是怎么唤醒呢,是用这个load的信息去做唤醒还是用之前的load的信息去唤醒
这其实就是在说如果一条指令和多个load指令有关系,那我如果记录robidx,会记录哪一个呢,如果存在直接联系,肯定是记录有直接联系的那个,但是如果是间接联系呢,我现在发现间接连接我甚至不知道把lpv记录在哪里,这种貌似就是没有办法的事情,毕竟之前的lpv是一个vector,可以记录所有的load指令,现在这种设计就是损失了广度提升了精度
等等我忽然有一个想法,就是每次有lpv的指令唤醒别人,就记录他的用pdest唤醒的psrc的lpv,然后由于两者有关系,所以后一条指令不会比他早的被选出,哎还是不太对,头疼(要不我就做没有推测唤醒的算了,哎
我忽然有一个很好的办法,可以比不做推测唤醒要更好,并且比较简单,其实上面说的所有问题,都出在间接唤醒的问题上面,间接唤醒的指令和那一条load没有直接的联系,这其实本质上不是间接唤醒的问题,这是直接唤醒的问题,是某些指令被load唤醒,啊,然后我知道这条指令有概率会唤醒错误,然后我在这条指令的某个src上标记他和某个load指令相关,但这个时候我用这条指令又推测唤醒了一些其他的指令,这种推测会一步步传递下去,就会导致一条指令可能和多个load指令相关,并且全部是推测,load指令回来的顺序又不确定,所以一个非常容易的解决办法就是不要让推测传播下去,就是在第二层的时候停止唤醒,直到获得cache信息的时候,再选择唤醒或者flush,其实假定的情况就是在获得cache信息的时候这条指令被发送的datapath,hit的时候就唤醒,miss的时候就flush,只是cache有可能晚几个周期到(bank导致的),这个时候就要延缓唤醒,等一等,这并不会造成什么性能损失,当miss的时候就不存在性能好或者不好的情况了其实,没有必要了
具体到做
rs就是普通的,当lsu的wakeupbus来的时候,唤醒包括他自己的所有指令,并给他们一个lpv标记☑️,存在lpv标记的指令(或者所有的load指令),都在被选出发射之后,不会被置compress标志,而只会置issued标志☑️,这样可以flush back指令,然后那条load指令进入lsu,并在一定时间给了一个cacheInfo来表示他hit或者miss,这时,存在lpv标记的指令可能会散播到 1.依然在RS里面 2.在RS中,但是这周期可能会被选出 3.在datapath中。当hit的时候,把在3的指令compress☑️,在1的指令lpv置空☑️,在2的指令会被选出并compress☑️;当miss的时候,把在3的指令flush回RS☑️并将issued置空☑️,并将所有的ready置空,在2的指令现在不会被选出☑️,在1的指令同样也是将所有ready置空;还有一种情况,就是没有发送cacheInfo之前,1不说,2就是正常被选出即可,3的指令此时不立马发送wakeup信息,而是等到cacheInfo信息到来的时候再决定是否wakeup☑️
写这里的时候发现一件事情,就是一条load指令被选出,给所有的置lpv的时候,不能给自己置lpv呀,因为自己被选出之后就已经会被进入到lsu了,除非说它和另外的load指令有关系,不过有关系的话这样子就更错误了,就会出现间接的错误
其他IPC优化
做了一点ipc优化,是某次不小心发现,当redirect的时候,也就是walk的时候,rename和decode阶段也是没有指令的,但是其实可以在redirect flush之后,rename和decode立马置ready,然后让指令阻塞在rename阶段来等待walk结束,可以比没有这个优化更快两周期(walk的时候),但是还没有测评他的时序情况
面积优化
后端占用面积太多,经过对冗余面积的处理,只处理掉了4%,目标应该是处理掉20%
占用面积最多的最主要原因其实就是多读写口的ram太多,从而被全部综合成lut了,所以lut爆炸了,我打算先对regfile做分bank处理,如果做完感觉不错,就再对rob做分bank处理
在指令进入datapath的时候,如果需要rs1/2,发送读请求给regfile,如果数据确实在regfile里面,过几个周期就能读出,如果不在里面,那指令就可以在旁路网络中获得数据(此时需要把数据锁起来maybe?),所以我估计是没有问题的
bank方案失败,一是我不会写多bank,另一个是貌似不需要多bank,我使用新的lpv方案综合,面积直降5%,然后我把lsu调成2发射了,面积降6%,之后修改存储的查询方式,不使用rvec和wvec,面积降了4%,基本上算上来就减了20%,从74%降到了54%(在有tlb的情况下)
基本上面积优化到这里就差不多了,我个人感觉绰绰有余了
时序优化(4)
虽然说不上是时序优化,毕竟时序才-0.8,但是主要是闲着没事,就做一下优化
一条是fence相关的,fence相关的直接无脑切,毕竟他的ipc不值钱
另一条竟然是alu的bypass,我想可以不可以对alu的运算顺序做优化,貌似有点麻烦,感觉最主要的问题还是出在datapath上面,虽然有一条确实是在alu里面,但是他被时序隐藏了,所以问题估计不是alu
诶不对,我之前用的是没有加推测唤醒的代码跑的综合,现在换掉了,变成-1.6了,悲伤
我忽然有一个非常nb的优化方式,这个优化方式我猜是可以优化时序的,并且同时还能优化ipc,就是将每一个datapath的指令全部分开握手,握手的粒度到每一条指令,而不是一组指令,这是第一个想法,第二个想法是多切一个流水级,这个想法来源是我发现只要是sram的行为,貌似就是会被综合成sram的,这个对面积很好,但是貌似也对时序一般,现在的关键路径还是ready的问题,我把它称之为ready时序地狱
开始干!
干完了,发现ipc不升反降,思考一番,猜想是没有很好的遵循oldest first的原则导致的,于是做了一些修改,但是之后触发了assert,原因是lsu需要保证store的一些顺序,但是这样每一个指令一个流水,可能会导致这个顺序崩坏,比如说某条前面的指令卡在了datapath,然后后面本来不能被选出的指令被选出了,就会触发assert,这个时候我感觉还是需要之前的方案,但是现在如果用lsu为2的方案,这个也并不是不能接受
最终我应该是做了四个优化,把最终的时序变成-0.2,但是只有4条负路径了
之后有莫名其妙的变成-0.8了,其实感觉最麻烦的还是这个compress,不管是candequpdate导致的关键路径,还是现在的select导致的关键路径,都会经过这个compress,所以我忽然想到一个好方法(灵机一动属于是)
就是他首先会计算出当前有多少个需要压缩的(包括compress和flush的数量),然后计算出newIdx作为压缩的新的index,假如我能把这个newIdx存着,而当前周期不压缩,而下周期使用这个newIdx来压缩并作出其他的操作,不知道这个想法可不可行
(喜欢晚上凌晨思考问题,因为没有东西会打扰自己)
首先当前周期计算出每个entry的newidx,然后变成一个vector,这个vec就是输入i,输出i的新位置,然后把这个vec保存到下一个周期,下周期根据这个类似于lut的vec来找出他的新位置,这周期来进行压缩,啊感觉好复杂,我能不能只对compress这么做呢,我思考一下
即,当这个周期,compress不做压缩直接写进去,下一个周期,根据compress和newidx来把其他项压缩
哇,竟然可以,之前的关键路径消失了,现在有一条mmu的关键路径,不过我暂时也不需要管他,不过看样子现在新的关键路径就只有-0.083了,神奇
啊经过后面一系列的优化,现在变成-0.49了,路径在wakeup和select之间,实在是不知道怎么优化了,现在如果不需要wakeup的话,时序就几乎是正的了(并非正的,-0.2),但是会损失0.2的ipc
然后就是这个-0.2是在sb里面
前端和dcache接入
很久没写了,经过了惊险的初赛,也不知道能不能进决赛,感觉性能有点寄,主要是lsu时序太差,bpu又是一个幼年版的
SoC
这个部分感觉就是给现有的soc添加设备,添加设备感觉分为几步
- 1,在soc中的bus中能开辟一个位置
- 2,能找到适合的控制器
- 3,能添加linux driver
感觉除了第二步,都挺难的对于我来说
如果是用verilator跑soc的仿真貌似不现实,他有专门的模拟soc仿真,但是仿真soc至少它chiplab不支持,所以就最多是vivado仿真+vivado上板
然后就是跑的程序,这个soc首先需要能跑功能性能测试,然后如果要fully tested,就需要linux或者裸机小游戏,之前ysyx我倒是记得有